Introduction[]
Files are simply a named repository for data. That can hold potentially large amounts of data, larger than available in memory. A file's lifetime is independent of process lifetime and can be used to shared data between processes. Files are also a convient method to input data into processes and save data from processes. It is considered the operating systems role to provide a file system which abstracts the application away from the hardware and provides a standard interface in which to deal and manage files. A file system does not only include tools that are part of the kernel but also user level applications to assist users with use of files.
Objectives of FS[]
- Provide a convenient naming system for files
- Provide uniform I/O support for a variety of storage device types
- Optimise performance
- Minimize or eliminate the potential for lost or destroyed data
- Provide a standardized set of I/O interface routines
- Storage device drivers interchangeable
- Ensure that the data in the file is valid
- Provide I/O support and access control for multiple users
- Support system administration (e.g., backups)
File Properties[]
Names[]
Operating system must provide a convient naming scheme for users to interface with files. File names are for the benefit of the user and provide a level of abstraction from physical locations. Extensions are a tool used in naming files that give users an understanding of what kind of data is contained in the file.
Structure[]
Byte sequence: OS considers this file to be unstructured. This simplies file management for the OS and allows users to dictact their own file structures. This is used on most modern operating systems.
Record sequence: Record is a series of bytes containing a specific type of data. File is made up of sequence of these. OS can optimise access to these records, but this file type is generally only found on old mainframes.
Key-based, tree structured: Tree of record, each record has a key associated with it. Data retrieval is performed by using the key. Most of this is now incorporated into modern databases.
Types[]
Regular files: sequence of bits
Directories: Files containing files
Device files: Devices that can be interacted with as files. Can be a bit stream
Executable files: Files that contain application code. At a minimum OS must recognise files that contain executable code.
File Access[]
Sequential: Read/write all data from the beginning. Can not jump around file but can read backwards.
Random: Data can be read/write in any order, at any location. Essential for databases.
Streams: Data is read/written sequentially or in blocks. Processes have 1 opportunity to read or write to a stream in an instance of time before it changes.
File Operations[]
File operations are often implemented as system calls. The following are some typical file operations support by modern operating systems.
- Create
- Open
- Close
- Delete
- Append
- Seek
- Get
- Read
- Write
- Set Attributes
- Rename
Directories[]
{kind=link}
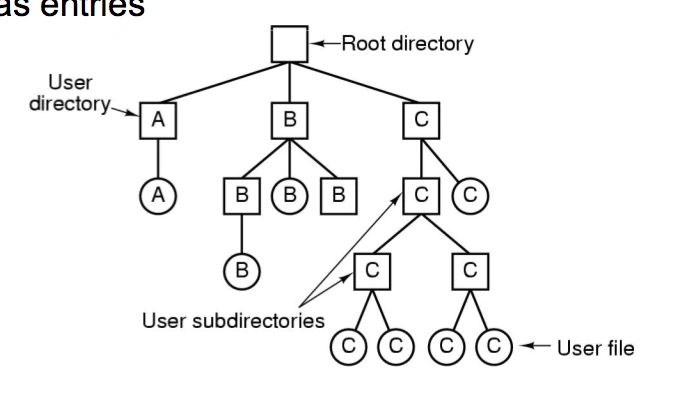
Hierarchical Directory Scheme
Directories are a file that is owned by the operating system. Contains several attributes of the files and provides a mapping between file names and the files themselves.
Most modern operating systems use a hierarchical directory scheme in which directories can have sub-directories.
Files are located by following a path from the root directory, this is called an absolute pathname. This allows files to have the same name if they are located in a different directory.
Absolute path names are tedious to work with and can become quite long. Relative path names solve this issue. A user specifies a directory they are currently working in, this is called current working directory, from that point onwards all path names are relative to that location.
Unix implements relative paths using dot notation. '.' = current directory '..' = parent directory.
Access Permissions[]
None[]
- User may not know of the existence of the file
- User is not allowed to read the user directory that includes the file
Knowledge[]
- User can only determine that the file exists and who its owner is
Execution[]
- The user can load and execute a program but cannot copy it
Reading[]
- The user can read the file for any purpose, including copying and execution
Appending[]
- The user can add data to the file but cannot modify or delete any of the file’s contents
Updating[]
- The user can modify, deleted, and add to the file’s data. This includes creating the file, rewriting it, and removing all or part of the data
Changing protection[]
- User can change access rights granted to other users
Deletion[]
- User can delete the file
Owners[]
- Has all rights previously listed
- May grant rights to others using the following classes of users
- Specific user
- User groups
- All for public files
Unix FS[]
Inodes[]
Each file on a unix-like FS is represented by an inode. The inode contains all the files metadata including access permissions, accounting information and a unique number with is used by the operating system to identify the file. Directories then contain mapping from file names to inode numbers.

{kind=link}
inode
Mode
Type - Regular file or directory Access mode - rwxrwxrwx
Uid
User ID
Gid
Group ID
atime
Time of last access
ctime
Time of creation
mtime
Time of last modification
size
Size of file in bytes
block count
Number of disk blocks used by file
reference count
The number of file-names which point to this particular inode. called hard-linking. It is to ensure that file is only deleted when there exist no more references to the file
direct blocks
Block numbers of the first 10 blocks in the file
single indirect
Block number of block containing block numbers
double indirect
Block number of block containing block numbers of blocks containing block numbers
triple indirect
Block number of block containing block numbers of blocks containing block numbers of blocks containing block numbers

{kind=link}
Block access
Inode Summary
- The inode contains the on disk data associated with a file
- Contains mode, owner, and other bookkeeping
- Efficient random and sequential access via indexed allocation
- Small files (the majority of files) require only a single access
- Larger files require progressively more disk accesses for random access
- Sequential access is still efficient
- Can support really large files via increasing levels of indirection
EXT2FS[]

A disk is divided up into a number of equally sized partitions(bock groups) all of which have the same structure, except for the first block which is a boot block.

{kind=link}
blockgroup
Each block group has the above formatting, containing the same number of data blocks. This structure aids recovery if one of the block groups were to fail and also reduces seek times as the inode and the data blocks are proximal.
Superblock - contains the size of the FS, block size etc. Also overall free block and inode count. May contain flag as to whether file system needs to be checked.
Group Descriptors - contain the location of the bitmaps, count free inodes and data blocks and the number of directories in the group.
Data Block Bitmap - used to identify used/unused data blocks
Inode Bitmap - used to identify used/unused inodes
Directories

{kind=link}
directory entry
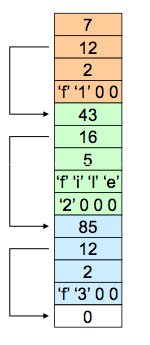
{kind=link}
Directories as previously mentioned are simply a file for translation inodes into file names. Here is the EXT2FS directory entry structure. The first element is the inode, followed by the length of the record, length of the name and then the type of file. The rec_len allows the FS to skip through the directory's listings.
Inodes can have more than 1 name linking to it, this is called a hardlink. The reference count in the inode is used to keep track of the number of hardlinks so when no more exist the file can be deleted.
Performance Optimisations
- Block groups cluster related inodes and data
- Pre-allocations of block- allocates 8 blocks no matter what is request and when operation is complete frees what is unused. Creates better contiguity.
Disk Management[]
There is a large gap between the speed of disk and processor and memory, this make effective management of disk an important issue. Disk throughput is extremely sensitive to the order data is requested and where the data is located on the disk. A disk is a mechanical device and the disck scheduler should be aware of it properties and geometry.
Disk geomtry[]


{kind=link}
A basic view of a harddrive is given on the left. As the tracks shift outwards from the centre more data can be stored per track.
Disk Operation[]
Wait Time: Process has to wait to be given access to device. Then it must wait for an appropriate I/O channel to become freee
Access Time: Disk requires time to position the head correctly, seek time. It then needs to wait for the disk to spin to the right location, rotational delay.
Transfer Time: It takes time to write and read data from the head.
Timing[]
Seek time = start up time, movement time, settling time. Seek time is the dominating factor in access time.
Rotational Delay = Average = 60/RPM/2
Track Patterns[]
Skew: When readin/writing sequentially the arm may miss the start of the enxt track as the arm must seek inwards or outwards. To avoid this the tracks are often skewed to account for the time it takes for the arm to move outwards. This ensures that there is not an extra rotation when writing sequentially.
Interlacing: It can take time to read the data then receive the next request for the following block. To over come this data maybe interlaced. See diagram below for single and double interlacing. Modern disks although will usually just read the whole track and cache the contents.

Arm Algorithms[]
Seek time is biggest contributer to access times, this should be reduced. For a single disk there will be at any one time a number of requests, processing them in the random order they arrive will negatively effect performance. If we schedule them correctly we can avoid seeking around the disk more than necessary.
FIFO
This strategy is fine if the data requested is from a small number of processes accessing sequential files. Otherwise it quickly deteriorates into random. It will never lead to starvation though.
Shortest Seek Time First
Performs substantially better than FIFO with many processes as it reduces the seek time dramatically. Although it can lead to starvation with some requests never progressing as they are away from the hub of disk activit.y
Elevator (SCAN)
Process requests in an acceding track order, from the middle to the outter edge. Only move the head in one direction until it reaches last track then move in opposite direction. Aimed to avoid starvation and performs better than FIFO but worst than shortest seek time. It makes poor use of sequential files on the down scan as it will require more rotations.
Modified Elevator (CSCAN)
Like elevator but only reads in one direciton. Better locality on sequential reads and read ahead cache.